

All models are wrong, but some are useful.
(George Box)
En 2019 nuestro modelo predijo la segunda vuelta con un márgen de error pequeño. Ahora nos aventuramos a predecir los resultados de la elección actual usando la misma metodología y este fue el resultado:
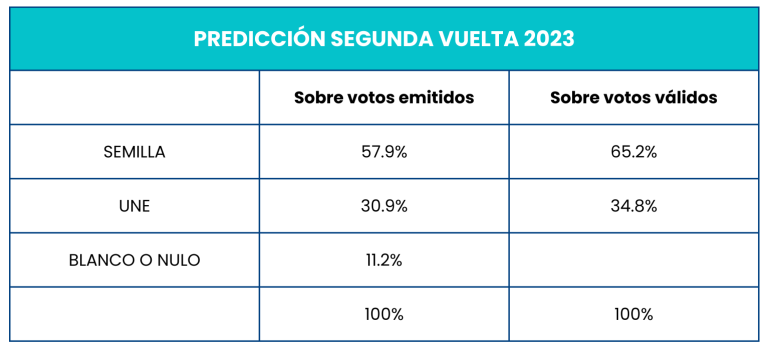
Para elaborar la predicción, utilizamos la metodología desarrollada en “De primeras a segundas vueltas: una predicción a manera de ensayo” de 2019.[1] En esa ocasión, pronosticamos correctamente los resultados de la segunda vuelta electoral utilizando una estrategia mixta: calculamos los votos obtenidos por la UNE directamente usando los votos de la primera vuelta (en el texto de 2019 mostramos claramente cómo los votos de ese partido crecen de forma más o menos consistente entre primera y segunda vuelta) y calculamos los votos obtenidos por el partido opositor, VAMOS, indirectamente usando la caída de votos entre la primera y la segunda vuelta (lo que aquí llamamos “abstencionismo entre primera y segunda vuelta”) y los votos en blanco o nulos. Los votos restantes fueron los que obtuvo el partido VAMOS.
Para la predicción de 2023, calculamos los votos obtenidos por la UNE en segunda vuelta de forma directa utilizando los votos que obtuvo en primera vuelta, y los votos de Semilla de forma indirecta calculando la caída de votos y los votos blancos o nulos. Los votos que sobren serán los votos que obtendrá Semilla.
Las variables se definen de la siguiente manera:
Abstencionismo entre primera y segunda vuelta
Es la caída de votos entre primera y segunda vuelta. Históricamente, se observa que siempre hay menos votos en segunda vuelta que en primera, en todos los departamentos. Esa caída de votos se modela como función de los “votos huérfanos”, es decir, de la cantidad de votos que obtuvo el resto de los partidos en la primera vuelta. La intuición es que mucha de la gente que no votó por ninguno de los candidatos que pasaron a segunda vuelta, se abstiene de votar en la segunda.
Blancos o Nulos
Los votos blancos o nulos en segunda vuelta se modelan como función de los votos blancos o nulos en primera vuelta. La intuición: mucha de la gente que votó en blanco o nulo en la primera vuelta hace lo mismo en la segunda.
Votos UNE
Los votos de la UNE se modelan como función de los votos obtenidos por la UNE en primera vuelta. Conociendo la cantidad de votos emitidos en primera vuelta y la cantidad de votos huérfanos para cada departamento, puede estimarse la cantidad de votos que serán emitidos en la segunda vuelta. También, sabiendo cuántos votos blancos y nulos hubo en la primera vuelta, se estima cuántos habrá en la segunda. Y lo mismo para la UNE: sabiendo cuántos votos obtuvo este partido en la primera vuelta, puede estimarse cuántos obtendrá en la segunda. Nótese que no hay un modelo para los votos de Semilla; estos se calculan por sustracción simple.
Si el lector técnico desea revisar los datos y los cálculos, puede descargar el siguiente proyecto de R. La carpeta contiene el código del procedimiento y los datos utilizados. Para los no versados en R, la carpeta también incluye un archivo de Excel con todo el procedimiento realizado.
La estrategia general se resume así:
- Plantear el siguiente par de ecuaciones, para cada departamento:
- Votos emitidos en segunda vuelta = votos emitidos en primera vuelta – abstencionismo entre primera y segunda vuelta
- Votos Semilla = votos emitidos en segunda vuelta – votos blancos o nulos – votos UNE
- Modelar los componentes subrayados de las ecuaciones (1) y (2) con regresiones lineales estimadas a partir de los resultados de la elección anterior (para la predicción actual se usaron los resultados de la elección del 2019; para la predicción de hace 4 años, se usaron los resultados de la elección del 2015).
- Aplicar los modelos a los datos de la primera vuelta actual para predecir los resultados de la segunda.
Reflexiones sobre la aplicabilidad (o no-aplicabilidad) de estos modelos
Complete ‘realism’ is clearly unobtainable, and the question whether a theory is “realistic”
enough can be settled only by seeing whether it yields predictions that are good enough
for the purpose in hand or that are better than predictions from alternative theories.(Milton Friedman, “Essays in Positive Economics”, 1953)
La observación empírica nos motiva a intentar predecir los votos de la UNE en segunda vuelta a partir de los votos que obtuvo en la primera. Como se ilustra en los diagramas de dispersión presentados a continuación, en las últimas dos elecciones el patrón ha sido muy similar: los votos de la UNE crecen de forma más o menos pareja en todos los departamentos entre la primera y la segunda vuelta (los puntos de las gráficas corresponden a los votos agregados por departamento). Resulta además que una regresión lineal simple se ajusta muy bien a los datos.
Figura 1. Resultados departamentales – Elecciones 2015
Votos UNE (en miles)
Figura 2. Resultados departamentales – Elecciones 2019
Votos UNE (en miles)
Hace 4 años, a manera de justificación teórica, argumentamos que el “Teorema del Votante Mediano” puede ayudar a explicar este fenómeno. El teorema predice que, en una contienda entre dos, ganará el candidato cuya propuesta concuerde más con las preferencias del “votante mediano”. En Guatemala, las últimas tres segundas vueltas presidenciales siempre han sido una contienda entre la UNE (mismo partido, misma candidata) versus un candidato más preferido por el votante mediano.
El teorema del votante mediano aún es aplicable. En este caso, consideramos que los extremos de la campana de Gauss que ilustra el teorema pueden referirse a la comodidad del votante con el sistema. En un extremo, aquellos que buscan preservar el sistema y lo defienden; en el otro, aquellos que buscan un cambio radical y derribar el statu quo desde la raíz. Las encuestas y opiniones en redes sociales reflejan la baja aprobación del ciudadano hacia el sistema político actual y la búsqueda de opciones que representen un cambio al statu quo, factor que favorece al partido Semilla, como refleja la predicción.
¿Funcionará el modelo esta vez?
Los estudiosos en el campo de las predicciones han demostrado varias veces que los modelos simples suelen predecir mejor que los complejos. La excesiva atención a los detalles coyunturales distrae y resulta perjudicial. Para fines predictivos, la parsimonia es lo recomendable.
Dicho esto, vale la pena leer esta cita del famoso libro de Philip Tetlock:
Superforecasting isn’t a paint-by-numbers method but superforecasters often tackle questions
in a roughly similar way—one that any of us can follow: Unpack the question into components.
Distinguish as sharply as you can between the known and unknown and leave no assumptions
unscrutinized. Adopt the outside view and put the problem into a comparative perspective
that downplays its uniqueness and treats it as a special case of a wider class of phenomena.
Then adopt the inside view that plays up the uniqueness of the problem. Also explore the
similarities and differences between your views and those of others—and pay special attention
to prediction markets and other methods of extracting wisdom from crowds. Synthesize all these
different views into a single vision as acute as that of a dragonfly. Finally, express your judgment
as precisely as you can, using a finely grained scale of probability.[2]
Invitamos a los super-forecasters guatemaltecos que conozcan más sobre este caso en particular a integrar información adicional y modificar (un poco) la predicción.
¡A ver qué pasa!
Fuentes de Datos
Resultados Electorales 2019: Datos y Democracia NDI Guatemala.
Resultados Electorales Preliminares Primera Vuelta 2023: Portal del Tribunal Supremo Electoral de Guatemala (actualización 29 junio 2023)
[1] Joseph Cole & Luz Angelina Rodríguez (2019). “De primeras a segundas vueltas: Una predicción a manera de ensayo”. BLOG Post, Onusprobandi, 29 julio de 2019.
[2] Philip E. Tetlock & Dan Gardner (2016). Superforecasting: The art and science of prediction. Random Hou
Aclaración:
En nuestra sección de blog, invitamos a personas expertas, externas a nuestra organización, a presentar sus análisis u opiniones sobre distintos temas. Las opiniones o análisis dentro de este texto, no reflejan ninguna postura institucional de Diálogos.